지식인 답변모음 3번에서 14.08.06 까지 답변했었고, 이후의 답변 추려봤습니다.
질문 제목 : 친구관리 db를 어떻게 짜야 할지 조언좀 해주세요.
내용 : jsp 페이지에서 a라는 사람의 db가 있는데 친구추가 페이지에서 b를 친구추가하면 b가 가진 정보를 a의 정보와 함께 나타내고 싶습니다.
그리고 친구를 끊으면 당연히 b의 정보는 사라지고 a의 정보만 남게요.. 조언 부탁드립니다.
답변 : 그리드로 관리 되는 화면인지 알아야죠. 또한 폼 형식이라면 개개인의 데이터만 나올 테니 함께 나타낼 순 없습니다.
굳이 나타내자면 폼을 더 만들순 있겠지만요. (여기서 폼은 html 의 TABLE 로 보면됩니다.)
최대 몇명까지 나타낼수 있을까요. 즉, 여러 친구를 보고 싶다면 그리드로 만들어지는게 맞고, 그리드 (목록) 라면 그리드 한개 로우 마다 친구의 id 값을 가지고 있게 한 후 그리드를 선택하여 친구 끊기 버튼을 누르면 끊을껀지 물어보는 메세지를 띄워주고 "예"를 누르면 그리드의 선택된 로우의 친구ID 값을 넘겨줘서 delete 쿼리를 태우면 됩니다.
delete 테이블명 where 친구ID = 그리드에서 선택된 친구ID값.
* 친구 관리 db를 구축하면서 나온 의문점에 대한 간단한 조언 이었습니다.
질문 제목 : 조인식 질문입니다.
내용 : SELECT DISTINCT 계약상황.*,B.수금액 FROM 계약상황 LEFT OUTER JOIN(SELECT 계약번호,SUM(수금액) AS 수금액 FROM 수금상황 GROUP BY 계약번호) B ON 계약상황.계약번호=B.계약번호,참여기술자 WHERE 참여기술자.참여자='전지현' and 계약상황.계약번호=참여기술자.계약번호" 계약상황,참여기술자,수금상황 테이블이 있고 수금테이블에 해당계약건들로 sum하여 계약테이블에 조인시키고 해당 참여기술자가 참여한 계약을 찾으려 하는데 조인식이 지원되지 않습니다. 라고 에러 메세지가 뜨네요.
참여기술자 요거를 FROM절에 어떻게 넣어야 정상적으로 처리되나요? ㅠㅠ.
답변 : SELECT DISTINCT A.*, B.수금액
FROM 계약상황 A LEFT OUTER JOIN(SELECT 계약번호, SUM(수금액) AS 수금액 FROM 수금상황 GROUP BY 계약번호) B
ON A.계약번호 = B.계약번호 INNER JOIN 참여기술자 C ON A.계약번호 = C.계약번호 WHERE C.참여자='전지현'; .
* 간략하게도 답해놨었군요. SQL ANSI 표준에 따라 작성된 쿼리라고 볼 수 있습니다. 물론 오라클 기준의 SQL문입니다.
질문 제목 : 오라클 EXISTS 어떻게 동작 하나요??
내용 : CREATE TABLE test1 (idx int, type char(1), title varchar(10));
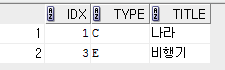
답변 : 타입을 서브쿼리의 조건으로 줬으니 type 과 조인을 하게 됩니다. 메인쿼리에서 a 테이블을 선언했고 where 절에서 서브쿼리를 사용했습니다.
a테이블의 한 건의 레코드와 b테이블의 모든 데이터를 비교하여 같은게 한개라도 있다면 값이 출력 됩니다. 즉, a 테이블의 레코드수 X b테이블의 레코드 수 만큼 크로스 조인이 된다고 볼 수 있지만 엄밀히 보면 크로스조인도 아니지요.
a테이블의 type C 와 같은게 있는지 확인하기위해 b테이블의 type 컬럼을 전부 비교하게 됩니다. b테이블에 type C 가 있기에
a테이블의 type C 가 출력되고 a테이블의 type D는 b테이블의 type 컬럼에 존재하지 않기에 넘어가고 다시 a테입르의 type E 는 b테이블에 type E 가 있기에 출력되는겁니다.
* 서브 쿼리 내에서 조인조건을 줘서 유효한 데이터를 필터링 해주는 기능인 exists 에 대한 질문이었습니다.
질문 제목 : 엑세스 기본키 뜻?! .
내용 : 엑세스에 기본키가 있잖아요! 그 기본키의 뜻이 궁금하네요~ (기본키에대한 정의).
답변 : 기본키는 테이블 내에 수많은 레코드가 존재할 경우, 각각의 레코드를 유일하게 구분할 수 있는 컬럼을
기본키(PK)라 정의하게 됩니다.
예를 들어 학생 테이블이 있을 경우
학번 이름 학과 .
001 아무개 수학과 .
002 돌팔매 영문과 .
003 김장군 수학과 .
004 홍길동 수학과 .
005 마동탁 영문과 .
006 김탁수 영문과 .
007 나이름 영문과 .
여기서 중복이 될 수 없는 값. 즉, 학번이 기본키가 되는겁니다. 기본키를 설정하는 이유는 학생 테이블과 관련된 다른 테이블과의 연결을 해주기 떄문입니다. 이를 관계라고 하며, 엑세스나 기타 데이터베이스는 서로 관계 있는 데이터들에 의해 여러테이블에 나뉘어진 데이터를 연결하여 사용할 수 있게 되는겁니다.
학생-자격증 테이블이 있다고 칩시다.
학번 자격증명 .
001 정보처리산업기사 .
001 정보기기운용사 .
006 워드1급 .
007 컴활1급 .
007 MOS .
위 테이블을 보면 학번이 있으며 학생 테이블과 학생-자격증 테이블의 학번은 같은 속성 값을 지니므로 연결이 가능하며 이는 곧 학생 테이블과 학생-자격증 테이블이 서로 관계가 있음을 뜻합니다.여기서 sql 문으로 원하는 데이터를 만들어 낼 수 있습니다.
수학과 학생의 학번과 이름, 자격증을 출력하시오.
select a.학번, a.이름, b.자격증명 from 학생 a, 학생-자격증 b where a.학과 = '수학과'; .
이렇게 할 경우
학번 이름 자격증명.
001 아무개 정보처리산업기사.
001 아무개 정보기기운용사.
와 같은 데이터가 나오게 됩니다. 즉 pk는 학생의 정보를 학생 한명당 한개만 가지고 있으며 모든 학생은 서로 다른 학번을 가지고 있기에 중복이 되지 않고. 중복이 되지 않는다는 것은 학생 한명한명을 학번으로 구분할 수 있음을 뜻하며 "테이블에서 레코드를 유일하게 구분할 수 있는 컬럼(혹은 컬럼들)이다." 라고 정의할 수 있습니다.
* PK에 대한 설명을 하고 있습니다. PK는 데이터간에 식별을 위한 키라고 보면 되겠습니다.
질문 제목 : 데이터베이스에서 사용하는 R에 대하여 자세히 알려주실분!.
내용 : 무슨 R 언어라고 하는거 같던데 여기저기 검색을 해봐도 이렇다할 정보가 없네요. 자세히 설명해주시면 감사하겠습니다!.
답변 : R 은 릴레이션. 관계를 말합니다. 현재 주류가 되고 있는 데이터베이스들은 관계형데이터베이스 모델을 기반으로 한 RDB 입니다. 보통 디비. 데이터베이스 라고 하면 이 RDB를 가르킵니다. 오라클이나 MS-SQL 등이 대표 제품에 속합니다.
이 R 은 특정 데이터를 여러 테이블로 나누는 정규화 와 밀접한 관련이 있습니다.
예를 들어 A 대학 B군 이라는 학생의 데이터가 있다고 가정하면.
학번 이름 주소 학과 수강과목.
A001 홍길동 우리집123 데이터베이스학과 물리.
A001 홍길동 우리집123 데이터베이스학과 C언어.
A001 홍길동 우리집123 데이터베이스학과 운영체제.
와 같이 나타날 수 있는데 이렇게 되면 학번, 이름, 주소, 학과 등의 데이터가 중복이 되어 불필요한 저장공간이 발생하게 됩니다.
이를 해소하기 위해서 즉, 중복을 최소화 하고자 하나의 테이블에 있는 데이터를 여러개로 나누는 정규화를 거치게 됩니다.
학생 테이블 에는 학번, 이름, 주소, 학과 번호가 들어가게 되고 학과 테이블에는 학과번호. 학과명. 학과위치 등의 정보가 들어가며 수강 테이블에는 학번 과목 으로써 데이터의 중복을 최소화 하게 됩니다. 이렇게 나누어진 테이블의 항목(컬럼) 을 보면 학생 테이블의 [학과 번호]는 학과 테이블의 [학과 번호] 와 연결이 가능합니다.
이렇게 서로 관계있는 항목을 통해 연결이 되어 있는 것이 R . 즉 관계 입니다. 수많은 데이터는 다수의 테이블에 나누어 저장이 되어있습니다.
* RDB에 대한 설명이라고 볼 수 있습니다. 주로 사용되는 데이터베이스 모델은 관계형 데이터베이스 모델이죠.
질문 제목 : 오라클 좀 알려주세요.
내용 : 한 로우에 A,B 값이 들어있습니다. SELECT 하면 A는 사과, B 는 배 로 보여주고싶습니다. 사과, 배 이런식으로요. DECODE 써도 안되고 어떻게 해야할까요.
답변 : 한개 로우 라는것은 컬럼 하나에 A,B 라고 들어가 있다는건가요. 아니면 한개 컬럼에 A 값 혹은 B 값으로만 들어가 있다는 건가요. 값이 한개 컬럼의 한개 로우에 사과,배 라고 들어갔을 때를 가정하여 처리했습니다.
select (case substr(a.col, 1,1) when 'A' THEN '사과' when 'B' THEN '배' END) || ',' || (case substr(a.col, 2,1) when 'A' THEN '사과' when 'B' THEN '배' END) AS COL .
from (select regexp_replace(col, '[ ,]') as col from tbl) a ;
한개 로우당 한개의 값만 가질 경우는 아래와 같이 쓰면 됩니다.
select case col when 'A' then '사과' when 'B' then '배' end as col from tbl;.
이상으로 2014.09.23 까지의 답변이었고, 꾸준히 이어나가겠습니다. 데이터베이스와 관련해서 간단한 질문정도는 언제든지 환영하며, 제가 모르더라도 여러 루트로 알아보고, 배운뒤에 답변을 도와드리도록 하겠습니다. 혹 부족한 답변이 보인다면 언제든 조언 및 지적 환영합니다.
'반짝 IT ↗ > 오라클' 카테고리의 다른 글
| 지식인 답변모음 - 데이터베이스 카테고리_9 (0) | 2018.04.13 |
|---|---|
| 지식인 답변모음 - 데이터베이스 카테고리_8 (0) | 2018.04.11 |
| 지식인 답변모음 - 데이터베이스 카테고리_6 (0) | 2018.04.10 |
| 지식인 답변모음 - 데이터베이스 카테고리_5 (0) | 2018.04.09 |
| 지식인 답변모음 - 데이터베이스 카테고리_4 (0) | 2018.04.09 |

